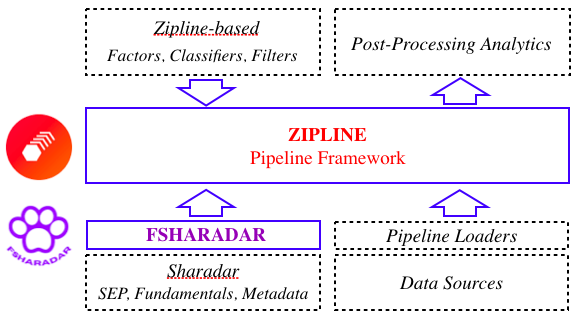
Within this framework, the Pipeline is a custom collection of cross-sectional trailing-window tasks (Factors, Classifiers, and Filters) propagated by Pipeline Engine through the backtest interval. The Zipline data layer is organized as a collection of named data bundles associated with different data sets. The FSharadar extension implements two bundles produced from Sharadar Equity Prices (SEP), Daily Metrics of Core US Fundamental Data, and asset metadata (e.g., name, type, cusip, etc.). The Pipeline Engine processes the pipeline tasks by accessing the related data bundles with the corresponding Pipeline Loaders.
- An overview of the platform user interface is available on the flounderteam github site.
- The VKY Analytics github repository flounder_sharadar_examples provides several IPython notebooks illustrating the usage of the fsharadar module within the research platform applications